3-3 チャンネル理論
idesのメタ形式変換において採用されているのは「チャンネル理論」です。
チャンネル理論とは、Dretskeによる情報意味論を基礎として、その数理をBarwise & Seligmanが整理したものです[1][2][3].
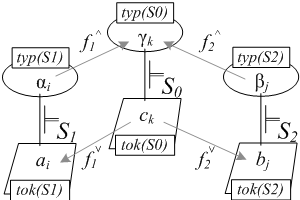
チャンネル理論は、複数の個体同士が情報をやりとりするときの構造をとても上手に説明できる理論です。 まず、「チャンネル」とは、複数の分類域が連携する様子を示しています。 その様子を示すために以下のような模式図が用いられます。 図中、tok(x)とは、分類域xにおけるトークンの集合で、typ(x)というのは、分類域xにおけるタイプの集合です。 図中で、トークンは、ai、bj、ckなどと示されており、タイプは、αi、βj、γkなどと示されています。 縦線が「トークンとタイプの関連」つまり、トークンが、あるタイプに分類される、ということを意味しています。
たとえば、人Aが「高田」という単語(トークン)を使ったとき、人Aの内部では、ある概念(タイプ)を示しているはずです。そのタイプを仮に[takada_1]と置きます。 つまり、
「高田」 |=A [takada_1]
(x |=A y とは、Aという分類域において、xがyに分類される、ということを意味します)。
一方、別の人Bにおいては、「高田」というトークンは、別の「高田」(仮にそれを[takada_2]と置きます)に分類されるかもしれません。 たとえば、[takada_1]とは「高田明典」のことであり、[takada_2]とは「高田たかし」のことである、というようなことです。 つまり、
「高田」 |=B [takada_2]
となります。 このとき、少々問題が生じます。それぞれの意味空間におけるトークンとタイプの関係を以下にChu-mapで示します (説明を簡便にするため、Chu-mapの本来の形式をもとに多少改変していますが、原理や仕組は同じです)。 ちなみに、Chu-mapとは、Barr,M や Seely,R.A.G によって提唱されたChu空間(Chu-space)の理論で使用される変換の仕組みの図式化のことをいいます。 Chuとは、Barrの学生であったPo-Hsiang Chuの名前に由来しているとされています。 どうしてChu-mapを用いて説明するのか、というと、チャンネル理論は、 その数理的な側面に関しては、(少なくとも私が理解している限りでは)Chu空間やChu変換と同じであるため、Chu-mapを用いて説明するほうが わかりやすいと考えたことによります。
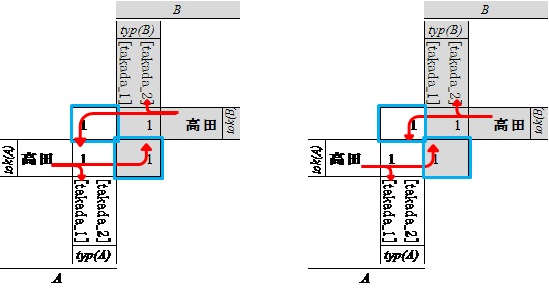 図中の青線で囲まれた部分が「チャンネル」です。人A、人Bは、それぞれ自分の意味空間の中で、「高田」を[takada_1]に分類したり、
[takada_2]に分類したりしていますが、そのトークン「高田」が、他の人からもたらされたものである場合、チャンネルによって変換します。
図中の青線で囲まれた部分が「チャンネル」です。人A、人Bは、それぞれ自分の意味空間の中で、「高田」を[takada_1]に分類したり、
[takada_2]に分類したりしていますが、そのトークン「高田」が、他の人からもたらされたものである場合、チャンネルによって変換します。
左側の場合、Aの分類域(図の白い部分)では、Bが使った「高田」というトークンは、[takada_1]に分類されます。 また、Bの分類域(図の灰色の部分)では、Aが使った「高田]というトークンは、「takada_2]に分類されます。 つまり、それぞれが、同じ「高田」というトークンに、別々の「意味」をあてはめるということになります。 このとき、人Aは、「高田」というトークンを、[takada_1]という意味(タイプ)で使っているのですから、当然、誤解が生じてしまいます。
右側の図のような構成になれば、その問題は解消します。 人Aは、[takda_1]という意味で「高田」というトークンを使い、人Bも、「Aが使った『高田』は、[takada_1]を意味する」と考えているということです。 また、逆も同様です。ここで重要なのは、そのようなチャンネルの存在により、人Aは「人Bが使ったトークンである『高田』は、[takada_2]のことだ」と 解釈することができ、同様に、人Bは「人Aが使ったトークンである『高田』は、[takada_1]のことだ」と 解釈することができるという点です。
つまり、これらの図中の青線で囲まれた部分(チャンネル)が適切に構成されていれば、誤解は生じないということになります。
そのようなことを実現するために、「階層構造意味空間モデル」が必要となります。 階層構造意味空間モデルによれば、それぞれの分類域を、自分の意味空間の下位の意味空間として構築することができるからです。
たとえば、以下の図では、システム本体(T0)が、話者T1と、T2とのあいだで、情報のやりとりをする際のチャンネルの単純な例を示しています。
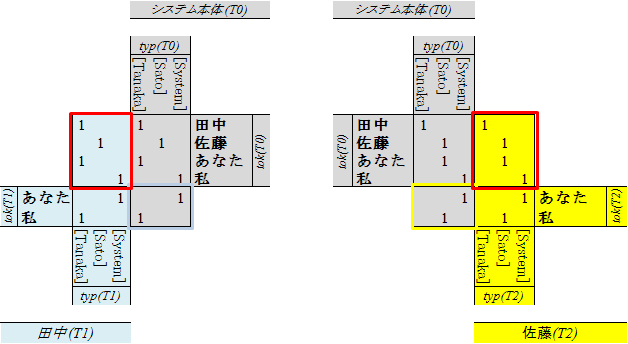 左側の図では、青の枠線で囲まれた部分がT1→T0のチャンネルであり、右側の図では、黄色の枠線で囲まれた部分がT2→T0のチャンネルです。
青で塗られた部分や、黄色で塗られた部分は、それぞれ、T1の意味空間(分類域)、T2の意味空間(分類域)であり、重要ではないわけではありませんが、
システム本体であるT0が何かを理解することとは、ほぼ関係ありません。それらは、T1における解釈、T2における解釈に関連するものではあるものの、T0の解釈には関連しないからです。
今ここで議論しているのは、「システム本体であるT0が、いかに適切な分類(トークンをタイプに割り振ること)ができるかということなので、T1とT2の分類そのものは、重要ですが、関係ない、ということです。
左側の図では、青の枠線で囲まれた部分がT1→T0のチャンネルであり、右側の図では、黄色の枠線で囲まれた部分がT2→T0のチャンネルです。
青で塗られた部分や、黄色で塗られた部分は、それぞれ、T1の意味空間(分類域)、T2の意味空間(分類域)であり、重要ではないわけではありませんが、
システム本体であるT0が何かを理解することとは、ほぼ関係ありません。それらは、T1における解釈、T2における解釈に関連するものではあるものの、T0の解釈には関連しないからです。
今ここで議論しているのは、「システム本体であるT0が、いかに適切な分類(トークンをタイプに割り振ること)ができるかということなので、T1とT2の分類そのものは、重要ですが、関係ない、ということです。
ただし「関係ない」というのは、多少語弊があります。上図で、青線や黄色線で囲まれた部分は、結局のところ、T1とT2の分類域(意味空間)のコピーです。 さらに、上図の赤い枠線で囲まれた部分は、T1とT2のそれぞれにおいて、T0が発したトークンがどのように分類されるかということを意味しています。それは、T0の解釈とまったく関係ないわけではありません。 なぜなら、T0とT1とT2の解釈(分類)は、基本的に一致していなくてはなりませんし、一致するように努力をすることになるからです。
そのような関係性のことを、チャンネル理論では「情報射」もしくは「情報同型写像」という概念で整理しています。詳細に関しては、高田の論文を読んでいただければと思いますが、それほど面倒な概念ではなく、 「適切な関係性を模索する」ということです。
そして、適切なチャンネルとは、それぞれの話者の分類域(意味空間)を、システム本体自身の中に、システム本体の意味区間とは区切られた領域として構築することによって 実現することができます。その様子を図示すると、以下のようになるでしょう。
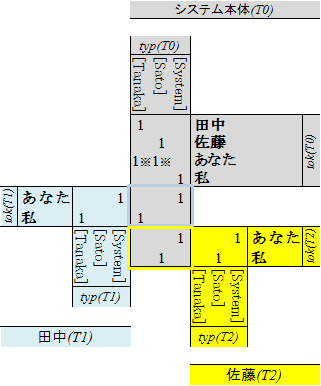 図中の灰色で示された部分が、本体内部に作られる分類用のデータであり、すなわち、話者それぞれの、(システム本体内部に作られた、下位の)「意味空間」です。T1、T2それぞれの内部で分類がどうなっているのかは本来はわかりません
(図の黄色で塗られた部分と、青で塗られた部分ですが、この図では「明らかである」ように描かれていますが、実際にはそれぞれの分類域のデータの総量は莫大で、全体像をつかむことなどほとんど不可能であるはずです)。
それでもシステム本体は、T1とT2とのやりとりによって、それらとの「チャンネル」を構築していくことできます。
そしてそのチャンネルとなるのが、idesでの意味空間であり、それが階層構造を持っているので「階層構造意味空間モデル」と呼びます。
図中の灰色で示された部分が、本体内部に作られる分類用のデータであり、すなわち、話者それぞれの、(システム本体内部に作られた、下位の)「意味空間」です。T1、T2それぞれの内部で分類がどうなっているのかは本来はわかりません
(図の黄色で塗られた部分と、青で塗られた部分ですが、この図では「明らかである」ように描かれていますが、実際にはそれぞれの分類域のデータの総量は莫大で、全体像をつかむことなどほとんど不可能であるはずです)。
それでもシステム本体は、T1とT2とのやりとりによって、それらとの「チャンネル」を構築していくことできます。
そしてそのチャンネルとなるのが、idesでの意味空間であり、それが階層構造を持っているので「階層構造意味空間モデル」と呼びます。
[1] Dretske, F., Explaining Behavior: Reasons in a World of Causes, Cambridge, Mass. The MIT Press, 1988.
[2] Dretske, F., Knowledge and the Flow of Information, Cambridge, Mass. The MIT Press, 1999[1981]:
[3] Barwise, J. & Seligman, J., Information Flow - The Logic of Distributed Systems, Cambridge University Press, 2008.
チャンネル理論は、複数の個体同士が情報をやりとりするときの構造をとても上手に説明できる理論です。 まず、「チャンネル」とは、複数の分類域が連携する様子を示しています。 その様子を示すために以下のような模式図が用いられます。 図中、tok(x)とは、分類域xにおけるトークンの集合で、typ(x)というのは、分類域xにおけるタイプの集合です。 図中で、トークンは、ai、bj、ckなどと示されており、タイプは、αi、βj、γkなどと示されています。 縦線が「トークンとタイプの関連」つまり、トークンが、あるタイプに分類される、ということを意味しています。
たとえば、人Aが「高田」という単語(トークン)を使ったとき、人Aの内部では、ある概念(タイプ)を示しているはずです。そのタイプを仮に[takada_1]と置きます。 つまり、
「高田」 |=A [takada_1]
(x |=A y とは、Aという分類域において、xがyに分類される、ということを意味します)。
一方、別の人Bにおいては、「高田」というトークンは、別の「高田」(仮にそれを[takada_2]と置きます)に分類されるかもしれません。 たとえば、[takada_1]とは「高田明典」のことであり、[takada_2]とは「高田たかし」のことである、というようなことです。 つまり、
「高田」 |=B [takada_2]
となります。 このとき、少々問題が生じます。それぞれの意味空間におけるトークンとタイプの関係を以下にChu-mapで示します (説明を簡便にするため、Chu-mapの本来の形式をもとに多少改変していますが、原理や仕組は同じです)。 ちなみに、Chu-mapとは、Barr,M や Seely,R.A.G によって提唱されたChu空間(Chu-space)の理論で使用される変換の仕組みの図式化のことをいいます。 Chuとは、Barrの学生であったPo-Hsiang Chuの名前に由来しているとされています。 どうしてChu-mapを用いて説明するのか、というと、チャンネル理論は、 その数理的な側面に関しては、(少なくとも私が理解している限りでは)Chu空間やChu変換と同じであるため、Chu-mapを用いて説明するほうが わかりやすいと考えたことによります。
左側の場合、Aの分類域(図の白い部分)では、Bが使った「高田」というトークンは、[takada_1]に分類されます。 また、Bの分類域(図の灰色の部分)では、Aが使った「高田]というトークンは、「takada_2]に分類されます。 つまり、それぞれが、同じ「高田」というトークンに、別々の「意味」をあてはめるということになります。 このとき、人Aは、「高田」というトークンを、[takada_1]という意味(タイプ)で使っているのですから、当然、誤解が生じてしまいます。
右側の図のような構成になれば、その問題は解消します。 人Aは、[takda_1]という意味で「高田」というトークンを使い、人Bも、「Aが使った『高田』は、[takada_1]を意味する」と考えているということです。 また、逆も同様です。ここで重要なのは、そのようなチャンネルの存在により、人Aは「人Bが使ったトークンである『高田』は、[takada_2]のことだ」と 解釈することができ、同様に、人Bは「人Aが使ったトークンである『高田』は、[takada_1]のことだ」と 解釈することができるという点です。
つまり、これらの図中の青線で囲まれた部分(チャンネル)が適切に構成されていれば、誤解は生じないということになります。
そのようなことを実現するために、「階層構造意味空間モデル」が必要となります。 階層構造意味空間モデルによれば、それぞれの分類域を、自分の意味空間の下位の意味空間として構築することができるからです。
たとえば、以下の図では、システム本体(T0)が、話者T1と、T2とのあいだで、情報のやりとりをする際のチャンネルの単純な例を示しています。
ただし「関係ない」というのは、多少語弊があります。上図で、青線や黄色線で囲まれた部分は、結局のところ、T1とT2の分類域(意味空間)のコピーです。 さらに、上図の赤い枠線で囲まれた部分は、T1とT2のそれぞれにおいて、T0が発したトークンがどのように分類されるかということを意味しています。それは、T0の解釈とまったく関係ないわけではありません。 なぜなら、T0とT1とT2の解釈(分類)は、基本的に一致していなくてはなりませんし、一致するように努力をすることになるからです。
そのような関係性のことを、チャンネル理論では「情報射」もしくは「情報同型写像」という概念で整理しています。詳細に関しては、高田の論文を読んでいただければと思いますが、それほど面倒な概念ではなく、 「適切な関係性を模索する」ということです。
そして、適切なチャンネルとは、それぞれの話者の分類域(意味空間)を、システム本体自身の中に、システム本体の意味区間とは区切られた領域として構築することによって 実現することができます。その様子を図示すると、以下のようになるでしょう。
[1] Dretske, F., Explaining Behavior: Reasons in a World of Causes, Cambridge, Mass. The MIT Press, 1988.
[2] Dretske, F., Knowledge and the Flow of Information, Cambridge, Mass. The MIT Press, 1999[1981]:
[3] Barwise, J. & Seligman, J., Information Flow - The Logic of Distributed Systems, Cambridge University Press, 2008.